How to Create High Quality Annotated Training Data for Radiology AI?
Deep learning with neural networks has potential of having very high productivity boosting impact on medical imaging for radiology. Although AI may never replace radiologist, AI will help improve productivity of radiologists in a very profound way.
Four types of organizations are involved in enabling AI in radiology:
- Incumbents like GE, Philips, Siemens, Nuance technologies, Teracon are building marketplaces to distribute AI algorithms from more than one vendor.
- AI startups are building deep learning algorithms to commercialize AI for radiology.
- GPU companies like NVIDIA are accelerating development of AI with free software development kits, and enable all other players to use their GPU hardware and GPU cloud.
- Research groups like Stanford Machine Learning Group, Ohio State University Medical College, and Department of Radiology, Mayo Clinicare bringing latest research to radiology AI.
There are some significant head winds for AI in medical imaging:
- Radiology imaging data often times contains personal health information (PHI). It requires adherence to strict regulation and HIPAA compliance laws. Here are some guidelines for what forms PHI under HIPAA compliance and common strategies to protect PHI.
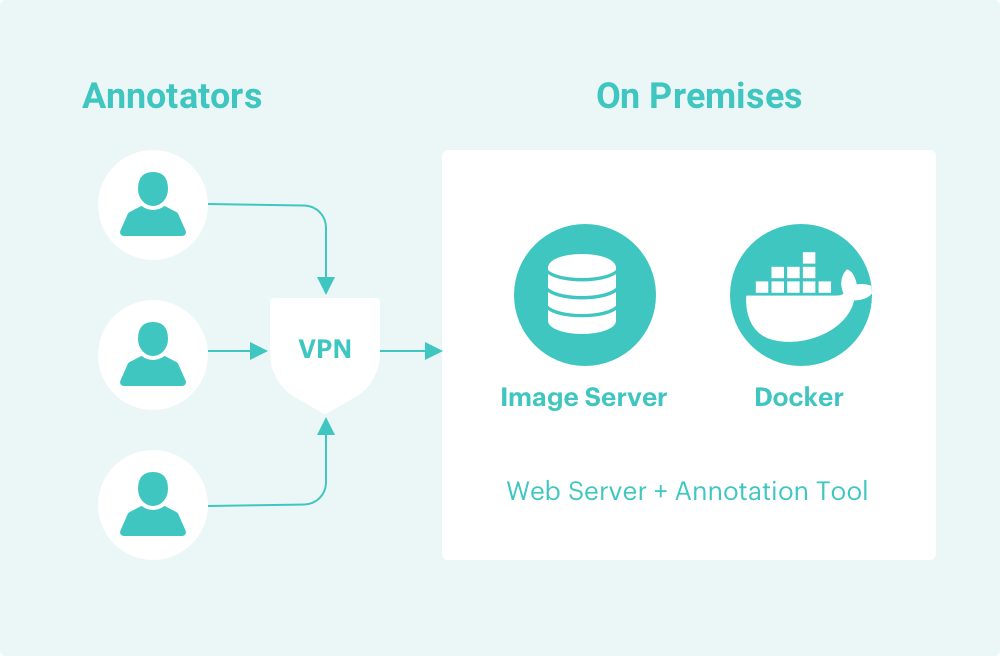
- Due to sensitivity of data, data needs to be housed in local network or under a VPN controlled network.
Solution
There is a general need for scalable data-management infrastructure. To help in this endeavor TrainingData.io has created a suite of tools to help data science teams create and manage large volumes of training data for radiology AI.
What makes a good training data management platform?
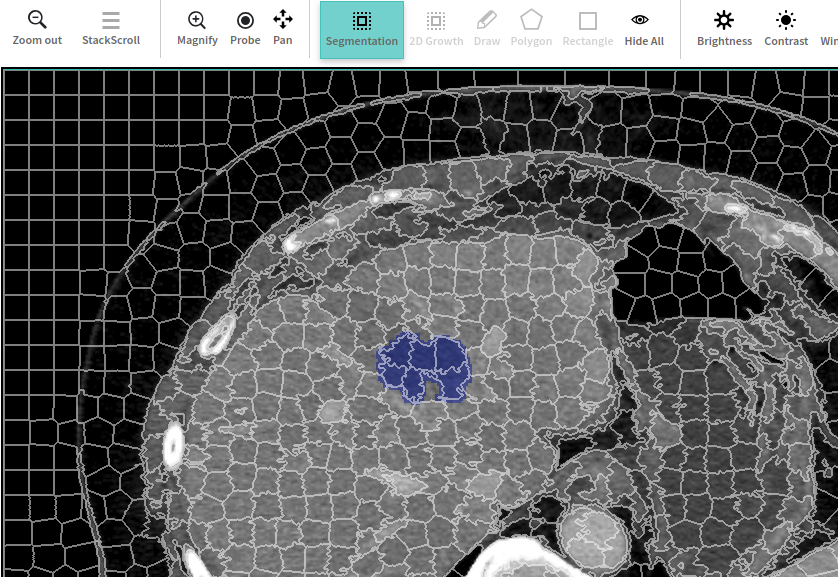
1. Pixel-accurate annotation tools
At TrainingData.io, we have built world’s first annotation tool that provide ability to create pixel-accurate annotations for Radiology image in DICOM format as shown in figure below:
2. AI-Assisted Annotations
NVIDIA Clara:
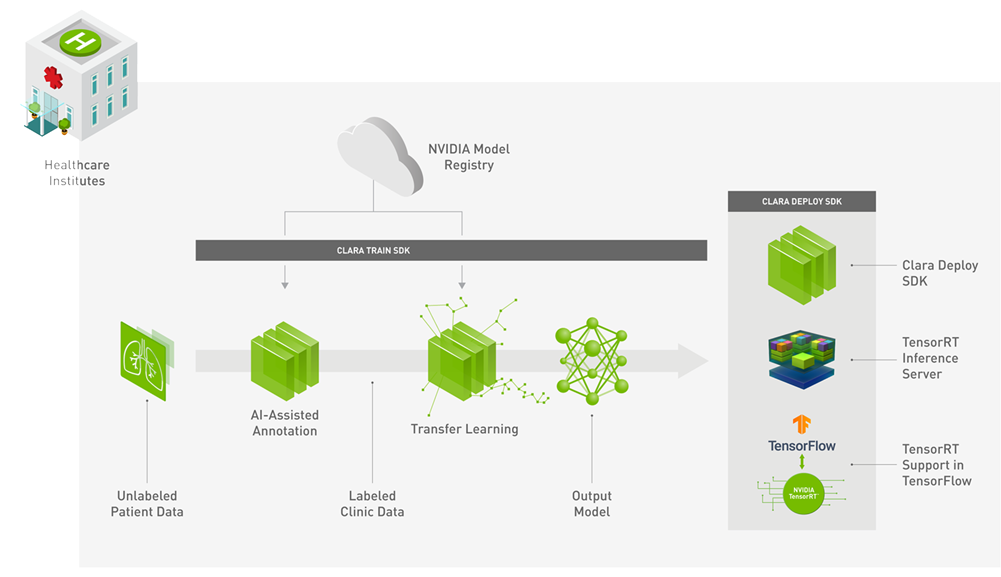
To generate auto-segmentation for any new dataset, TrainingData.io has built a user interface as shown in video below:
NVIDIA Clara web server provides an interface to TensorRT in form of virtualized services that can receive data in DICOM format or nifti format and return the results of the annotation.
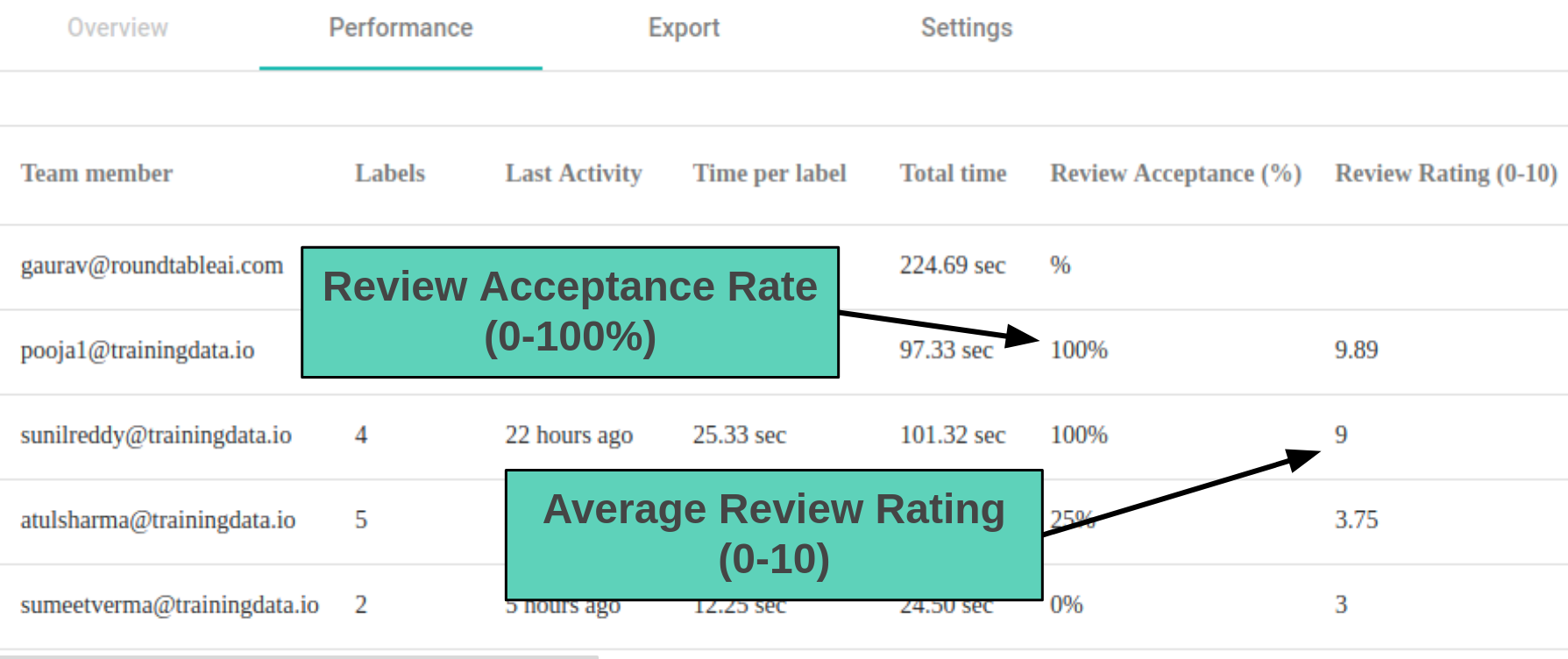
3. Annotator’s Performance Management
Measure, record and analyze annotator’s performance on every individual task, asset and label. Compare performance of multiple annotators on same task. Distribute labeling work among multiple labelers and observe consensus among their work. Seed annotation tasks with golden data set. Report performance of annotator on golden data set.
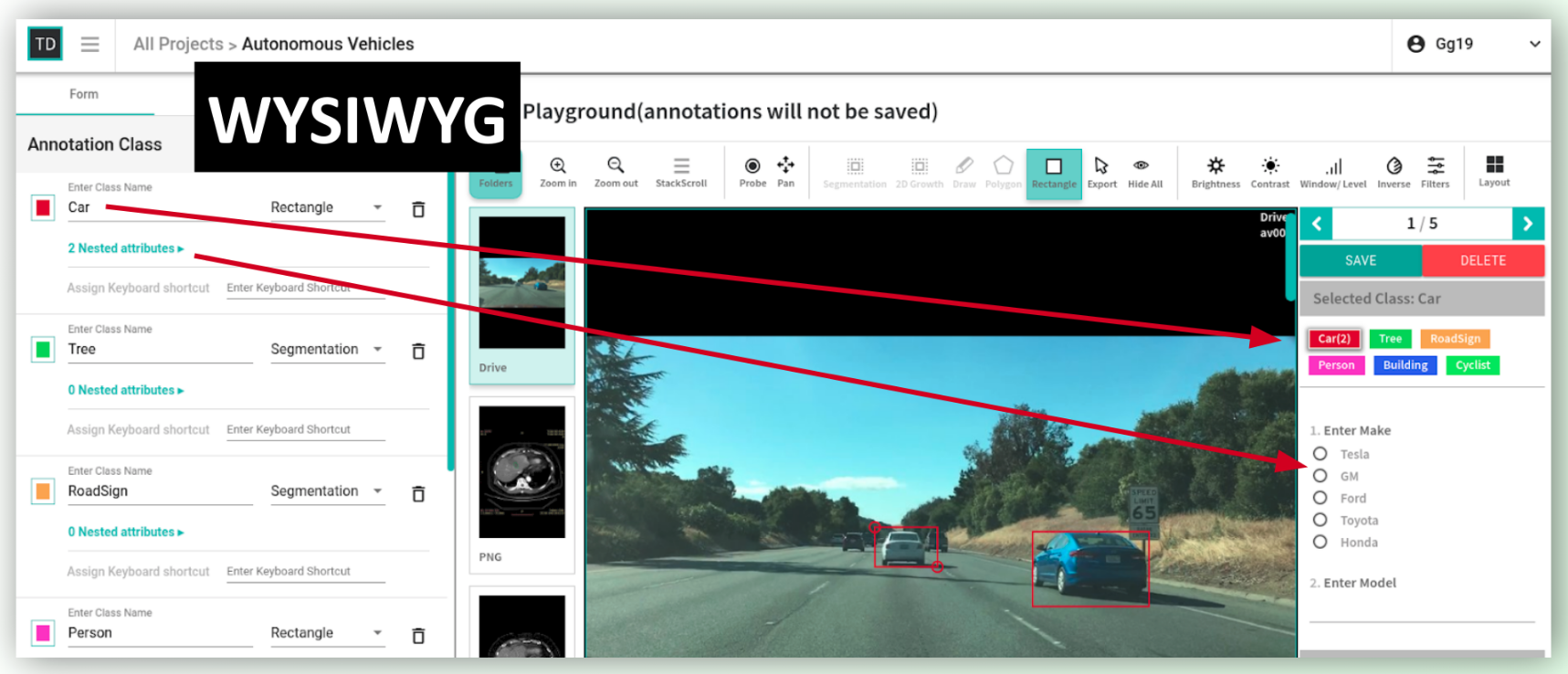
4. Labeling Instruction Builder
In order to give labeling task to freelance annotators, data science team needs to define specifications of a labeling task. Those specifications need to be converted to a user-experience. In TrainingData.io application specification builder is called labeling instruction. Labeling instruction is a list of objects that a data-scientist wants human-labelers to find in an image. Objects can have properties like color, size, shape etc. Data-scientist wants to present these properties in question-and-answer HTML form to the annotator.
5. Data security and privacy
To support strict security requirements, TrainingData.io has built a hybrid workflow, where imaging training data and annotation tools run as Docker image inside a firewalled network. Quality control workflow with dataset management is hosted in-cloud. This allows data-scientist to manage the annotation-workflow with global workforce, while keeping data secure within their own network.