Training Data Quality Control: Annotator Performance Management
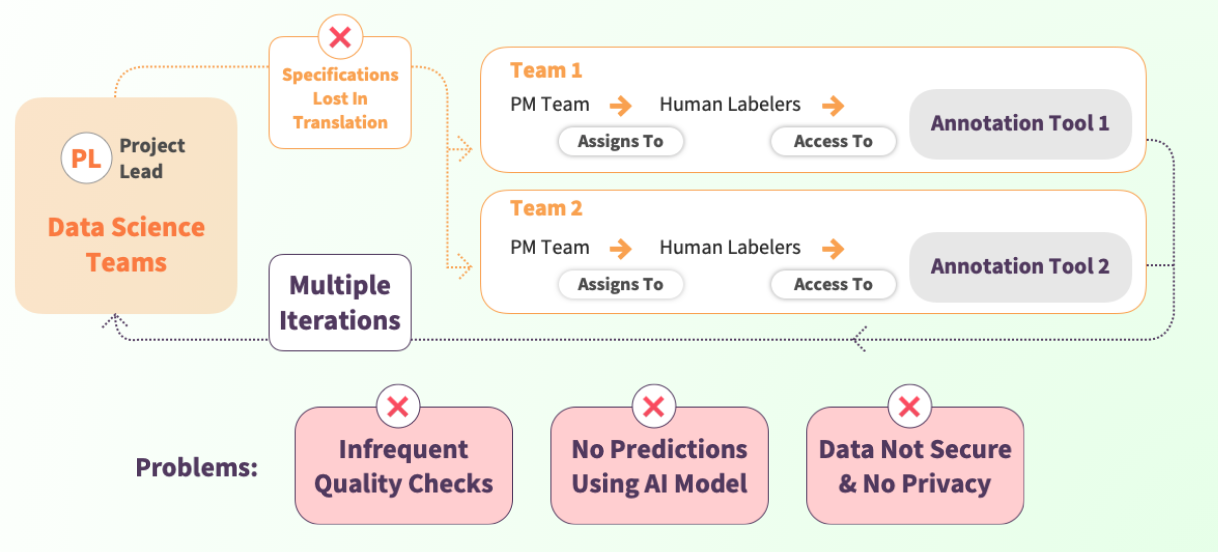
To produce state-of-the-art machine learning models, data-science teams need to feed millions of annotated images to deep learning systems. Today machine learning models suffer from lack of high quality labeled training data. This is because labeling process has very high error rates, in some cases as high as 35%.
Why does labeling process have high error rate?
Image and video annotation involves boring and repetitive tasks. Any work performed by freelance workforce is difficult to manage for its outcome. To label millions of images data science team needs to:
- Prepare specifications of the labeling task. Specifications of a labeling task are usually given in written format. This is highly error-prone because there can be multiple interpretations of a written specification. More often than not specifications are wrongly interpreted by the outsourcing-labeling-company.
- Data science teams receive results of a labeling task in batches as a result inspections-for-quality are very infrequent.
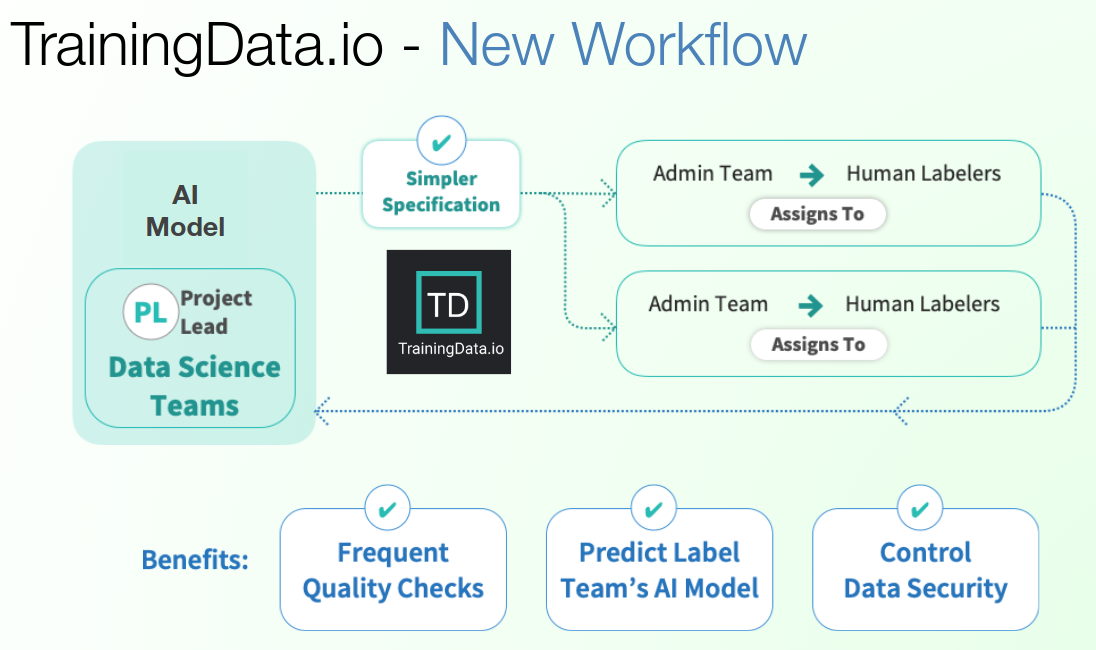
How to reduce error rates in data labeling?
To reduce error rates in data labeling:
- Data science team needs to ensure labeling-task-specifications given by data-scientist are converted into a productivity enhancing user-experience for the annotators.
- Data science team needs to provide, to the annotators, high precision labeling tools with excellent user-experience.
- Data science team needs to inspect performance of annotators as frequently as possible. In this article we will go in details of how to inspect work performed by annotators.

How to engage multiple annotators in an annotation task?
In TrainingData.io application data-science team can add an new annotator by going to project settings and adding email address of an annotator.
Annotator will receive an invite in their email with a link to the project. When they click on the link, it will take them to annotation tool. Once they have saved their annotations, TrainingData.io application will aggregate statistics of their performance. Following metrics will be aggregated:
- Total number of labels created by each individual annotator.
- Total amount of time spent on the project
- Time spent per label
- Consensus with other annotators.
Review System: How to Review Work of an Annotator?
For high quality machine learning models, data-science team needs to feed high quality labels to deep learning system. High quality labeling is difficult to achieve because free-lance annotators produce different quality of output. To monitor their quality of work, data-science team needs to review all or part-of work done by each annotator.
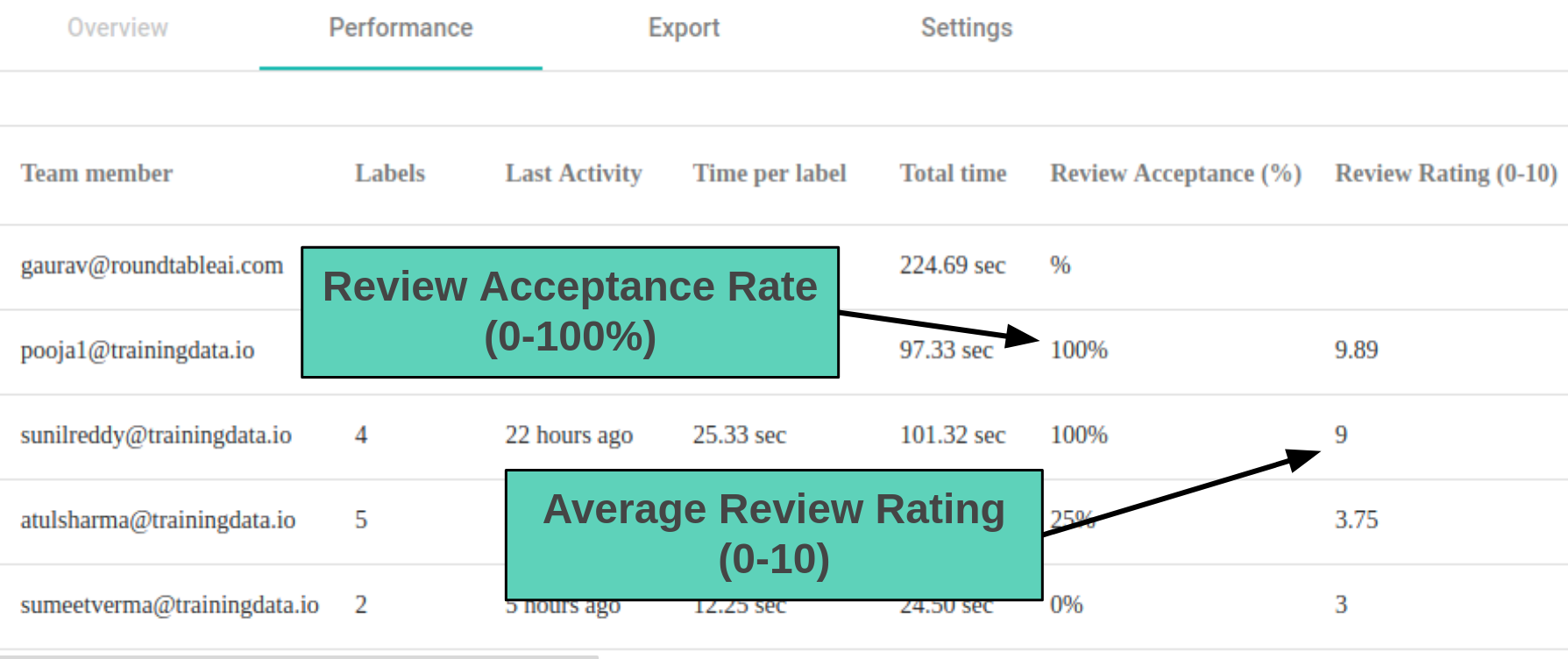
Below given screenshot shows an annotation task performed by 5 annotators. Data-science team has not reviewed work of annotators. “Review Acceptance” and “Review Rating” are empty:

Video below shows a data-scientist reviewing work of each annotator image-after-image.
After data-science team has reviewed work of each annotator you can compares “Review Acceptance” and “Review Rating” of each annotator. This allows data-science teams to make informed decisions about which individuals are best suited for a labeling task.
This story was first published in TrainingData.io Blog