Sensor Fusion & Interpolation for LIDAR 3D Point Cloud Data Labeling
Autonomous vehicle development has seen higher volume and greater accuracy of sensory data being recorded from hardware sensors. Sensors have gone up in number. Additionally newer generation of sensors are recording higher resolution and more accurate measurements. In this piece we will explore how sensor fusion allows greater degree of automation in data labeling process that involves humans-in-the-loop.
All autonomous vehicles (AV) use a collection of hardware sensors to identify the physical environment surrounding them. The hardware sensors include camera or a collection of cameras strategically placed around the body of the vehicle to capture 2D vision data, and some form of RADAR placed on top of the vehicle to capture 3D position data. There are a few vendors like Tesla who believe vision data is enough for a vehicle to identify its environment. Other vendors use LIDAR sensors to capture 3D position data for the objects surrounding the vehicle. Fusion of 2D vision data and 3D position data gives an AV system precise understanding of its surrounding environment.
Developing precise understanding of its surrounding environment is the first component of an AV system. Image below shows all the important components of an AV system.
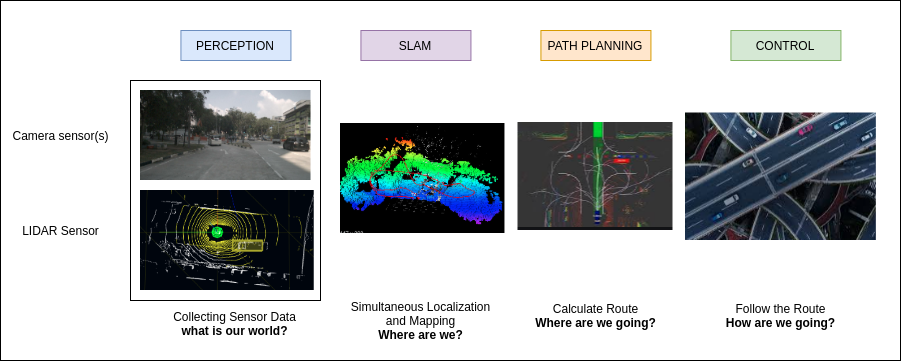
Sensor Fusion
Computer vision is a branch of computer science that uses camera or a combination of cameras to process 2D visual data. This allows computers to identify cars, trucks, cyclists, pedestrians, roads, lanes marking, traffic signals, building, horizon. Camera data is 2D in nature, and it does not provide distance of an object. Although focal length and aperture of a camera sensor can be used to approximate the depth of an object, it will not be precise because there is intrinsic loss of information when a 3D scene is captured by a camera sensor onto a 2D plane.
Radar technology has been in use in places like air traffic management to locate flying objects. Radar can be used to estimate location and speed of an object. It cannot be used to classify an object as a car, person, traffic signal, or a building because it has low precision. Lidar is a hardware that uses laser technology to estimate the position and speed of objects in the surrounding. Lidar is able to generate point cloud of upto 2 million points per second. Due to higher accuracy Lidar can be used to measure shape and contour of an object.
While RGB data from camera is lacking depth information, point cloud data generated by Lidar lacks texture and color information present in the RGB data. For example in a point cloud data, contour of a pedestrian 20 feet away might be a blob of points that can be identified as multiple different objects as shown in rendering of point cloud below. On the other hand a shadow ridden low quality partial visual information gives a hint that the object is a person as shown in image from a camera below.


When fusion of visual data and point cloud data is performed, the result is a perception model of the surrounding environment that retains both the visual features and precise 3D positions. In addition of accuracy, it helps to provide redundancy in case of sensor failure.
Fusion of camera sensor data and Lidar point cloud data involves 2D-to-3D and 3D-to-2D projection mapping.
3D-to-2D Projection
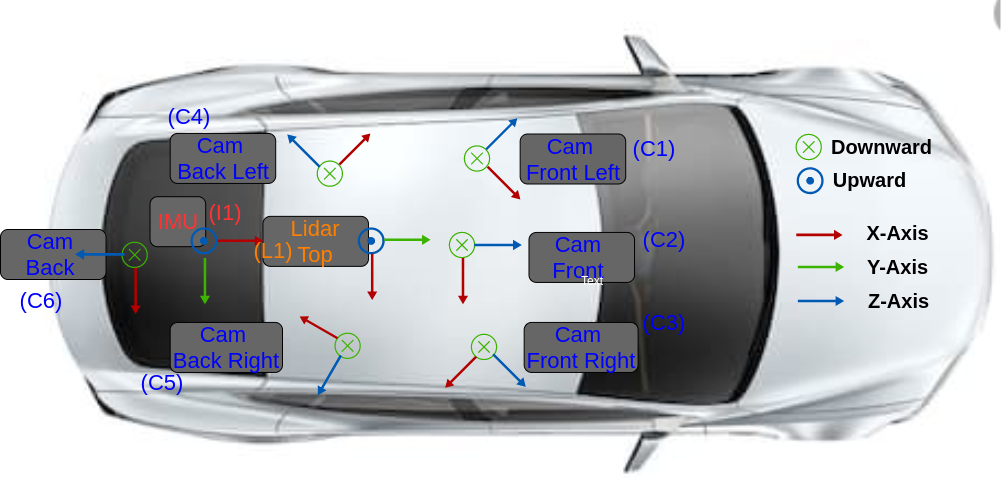
Hardware Setup
We start with the most comprehensive open source dataset made available by Motional: nuScenes dataset. It includes six cameras three in front and three in back. The capture frequency is 12 Hz. The pixel resolution is 1600x900. The image encoding is one byte per pixel as jpeg. The camera data is generated at1.7MB/s per camera footage. One Lidar is placed on top of the car. The capture frequency for lidar is 20 Hz. It has 32 channels (beams). Its vertical field of view is -30 degrees to +10 degrees. Its range is 100 meters. Its accuracy is 2 cm. It can collect upto 1.4 million points per second. It’s output format is compressed .pcd. Lidar’s output data rate is 26.7MB/s (20byte*1400000).
Important Links
Dataset Page: https://www.nuscenes.org/overview
Paper URL: https://arxiv.org/pdf/1903.11027.pdf
Devkit URL: https://github.com/nutonomy/nuscenes-devkit
Understanding Reference Frames & Coordinate Systems
In order to synchronize the sensors one has to define a world (global) coordinate system. Every sensor instrument has it’s own reference frame & coordinate system.
- Lidar has it’s own reference frame & coordinate system L1,
- Each camera has it’s own reference frame & coordinate system C1, C2, C3, C4, C5, C6.
- IMU has it’s own reference frame & coordinate system I1.
- For the purposes of this discussion here, ego vehicle reference frame is the same as lidar reference frame.
Define world reference frame & coordinate system
World reference frame (W1) is global reference frame. For example one can select lidar’s first frame as center (0, 0, 0) of the world coordinate system. Subsequently every frame from lidar will be converted back to world coordinate system. Camera matrices M1, M2, M3, M4, M5, M6 will be formulated to convert from each camera coordinate system C1, C2, C3, C4, C5, C6 back to world coordinate system W1.
Convert 3D Point Cloud Data to World Coordinate System
Each frame in lidar reference frame (L1) will be converted back to world coordinate system by multiplication with ego frame translation & rotation matrices.
Convert from World Coordinate System to Camera Coordinate System
Next step is to convert data from world reference frame to camera reference frame by multiplication with camera rotation & translation matrices.
Convert from 3D Camera Coordinate System to 2D Camera Frame
Once the data is in camera reference frame it needs to be projected from 3D camera reference frame to 2D camera sensor plane. This is achieved by multiplication with camera intrinsic matrix.
Result: Accurate Annotations
As shown in the video below the fusion of lidar point cloud data, and camera data allows annotators to utilize both visual information & depth information to create more accurate annotations.
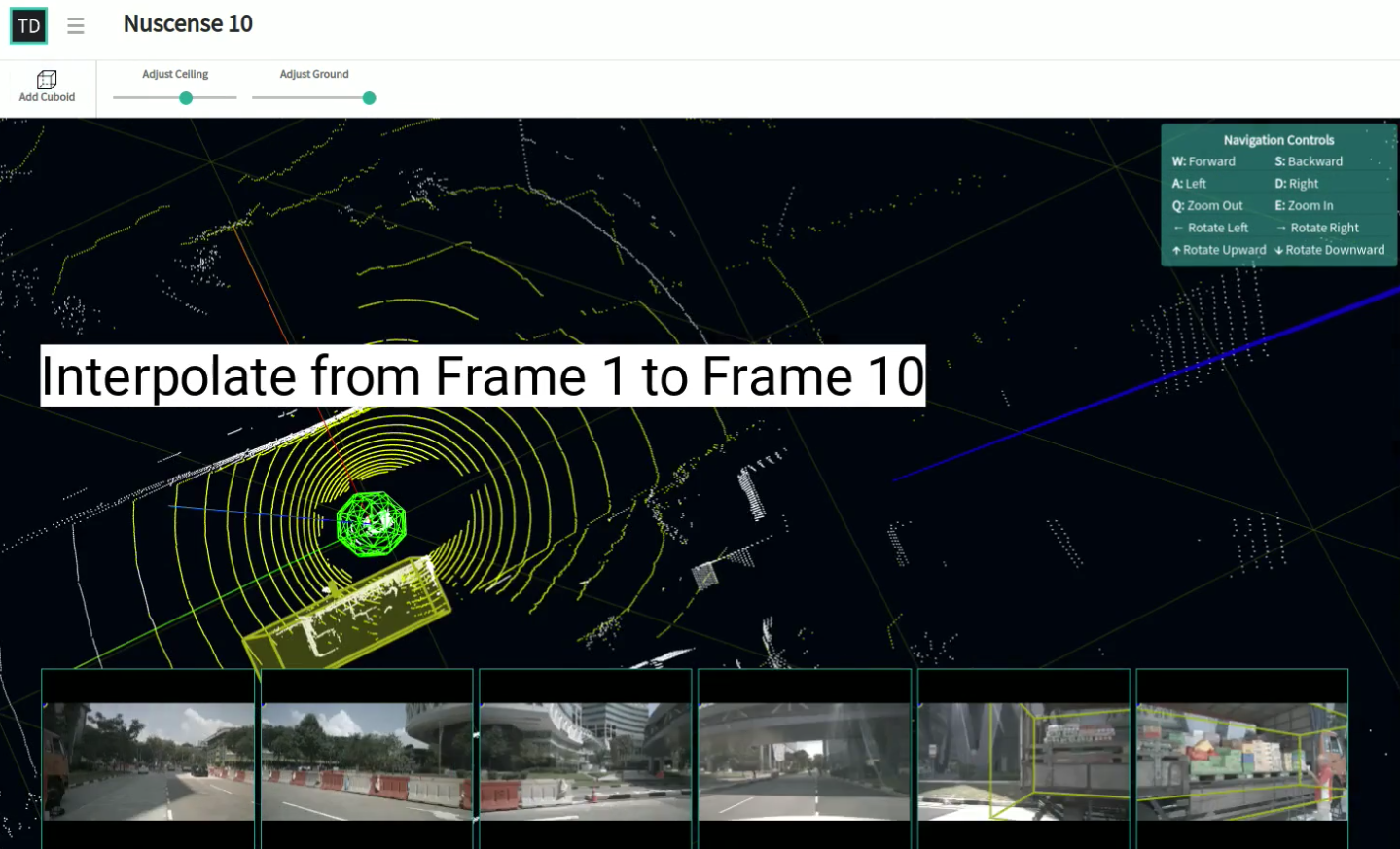
10X Speedup in labeling: Interpolation of annotation between frames
One of the the most challenging task in development of autonomous vehicle systems is to manage humongous volumes of data used for training the neural networks. As the classification and detection accuracy improves the amount of new training data needed to further improve the performance grows exponentially. To increase speed and reduce cost of annotating new training data, annotation tool can provide automation. One example of automation is interpolation of annotations between frames in LIDAR point cloud tool.
The sensor data being generated has high degree of accuracy. The lidar point cloud data is accurate to plus-or-minus 2 cms. The camera data is recorded at 1600 x 900 pixel resolution. High accuracy level allows annotation tool to provide semi-automatic techniques to reduce the manual effort required in data labeling. As an example consider annotation of 10 consecutive frames of point cloud data. Each lidar frame is accompanied by six camera frames. Human annotators use the annotation tool to fit a truck inside a cuboid in frame 1 and frame 10. Based on position of the cuboid in frame #1, and frame #10, the annotation tool can automatically interpolate position of the cuboid from frame 2 to frame 9. This significantly reduces the amount of work required from the human labellers. Such semi-automatic techniques can boost productivity, increase speed, and reduce the cost of building AI.